
Banco de Dados - SQL Server
Aumente a performance do SQL Server
Aprimore suas informações de estatísticas e índices para otimizar a performance do banco de dados.
por Mary V. HookeA velocidade costuma ser uma preocupação quando se trabalha com banco de dados. Muitos fatores contribuem para a performance de seu banco de dados: o sistema operacional, problemas de hardware (como memória e espaço em disco) e até o design do aplicativo que está acessando o banco de dados. O projeto de seu banco de dados também tem um papel importante na performance.
Neste artigo, falarei sobre alguns dos procedimentos que você pode adotar para melhorar a performance do banco de dados do SQL Server. Falarei especificamente sobre a capacidade do SQL Server 2000 de criar índices em Views e sobre como configurar apropriadamente seus índices usando o ITW (Index Tuning Wizard). Ensinarei o que fazer para garantir que suas consultas se beneficiem ao máximo das vantagens de informações de estatísticas e de índice.
A performance deve ser levada em conta desde a fase inicial do projeto do banco de dados. No entanto, você poderá fazer modificações para melhorá-la mesmo depois de ter iniciado a produção do banco de dados. Os índices são objetos de banco de dados que otimizam a busca e a classificação dos dados. Índices configurados apropriadamente podem fazer uma enorme diferença no tempo levado para inserir ou extrair dados do banco de dados. O ITW pode ajudá-lo a determinar como implementar índices no banco de dados para aumentar ao máximo a performance.
O ITW pode ser usado para recomendar a melhor configuração de índices para um banco de dados em função de uma carga de trabalho específica. Uma carga de trabalho é um script SQL ou rastreamento SQL que você salva em um arquivo externo.
As recomendações do ITW serão feitas de acordo com as cargas de trabalho e, por isso, é importante que você prepare antes as informações apropriadas. Provavelmente, a maneira mais fácil e completa de criar uma carga de trabalho para o ITW é salvar um rastreamento SQL criado pelo SQL Profiler. Um recurso novo do SQL Server 7.0, ele registra a atividade do servidor usando os filtros e critérios que você forneceu. Certifique-se de que seu rastreador SQL esteja registrando as atividades comuns do banco de dados quando criar um rastreamento com o SQL Profiler para ser usado com o ITW. Em outras palavras, escolha uma hora em que o banco de dados não esteja especialmente sobrecarregado ou subutilizado. O tempo que você levará para executar os rastreamentos dependerá especificamente do seu sistema. Em alguns casos, poderá levar apenas uma hora para executar o rastreamento e capturar uma representação precisa da atividade do sistema. Em outros, poderão ser necessários vários dias para registrar todas as variações padrão das atividades ocorridas no banco de dados.
Acione o ITW
Uma vez criado o arquivo de carga de trabalho a ser usado, acione o ITW selecionando um servidor na árvore no modo de visualização em árvore do Enterprise Manager. Selecione Wizards no menu Tools, abra o menu drop-down do nó Management na árvore de visualização e selecione Index Tuning Wizard. Será exibida a tela de boas-vindas do ITW. A segunda tela do ITW permite que você especifique qual servidor e banco de dados deseja analisar. Você tem duas opções adicionais nessa tela: Keep All Existing Indexes e Perform Thorough Analyses. Desmarcar a opção Keep All Existing Indexes permitirá que o ITW faça as recomendações de indexação. No entanto, o ITW pode sugerir a exclusão ou alteração de alguns dos índices existentes. Ou seja, se você não quiser alterar seus índices, deixe essa opção selecionada. Selecionar a opção Perform Thorough Analyses fará com que o ITW realize a análise mais completa e abrangente possível. Embora essa opção possa apresentar resultados melhores, provavelmente exigirá mais tempo para ser concluída. Além disso, ela também pode causar uma sobrecarga no servidor. Por esses motivos, se você escolher executar a análise completa, sugerimos que o faça em um servidor de teste ou, no caso de usar o seu servidor de produção, que a execute fora dos horários de pico.
A terceira tela do ITW pede que você especifique a carga de trabalho com a qual deseja trabalhar. Se estiver usando um arquivo criado pelo SQL Profiler, selecione o botão da opção My Workload File e use a caixa de diálogo File para localizar o arquivo em que salvou o rastreamento. Você também pode definir algumas opções avançadas nessa tela clicando no botão do comando Advanced Options. Essas opções incluem a especificação da quantidade máxima de espaço em disco a ser usada pelos índices recomendados e o número máximo de consultas no seu arquivo de carga de trabalho em que deverá ser feita a amostragem. Na quarta tela, você especifica as tabelas para as quais deseja receber recomendações de índice. A seleção de poucas tabelas poupará tempo e o ajudará a se concentrar nas áreas mais problemáticas.
No entanto, se estiver esperando que o ITW ofereça sugestões sobre como otimizar o banco de dados como um todo, você provavelmente escolherá selecionar todas as tabelas de seu banco de dados. A próxima tela do ITW mostra as recomendações de índice com base nos critérios que você forneceu (observe a Figura 1). Essa tela lhe oferece a opção de implementar imediatamente as recomendações (programando a execução para mais tarde) ou de salvar o script de execução em um arquivo externo.
Figura 1: Otimize com o ITW. O ITW (Index Tuning Wizard) fornece as recomendações necessárias para que você configure os índices de seu banco de dados em função de um arquivo de carga de trabalho específico. Você pode implementar essas recomendações imediatamente ou agendá-las para serem executadas mais tarde. O SQL Profiler constitui uma ferramenta valiosa na criação dos arquivos de carga de trabalho que serão analisados pelo ITW.
A velocidade costuma ser uma preocupação quando se trabalha com banco de dados. Muitos fatores contribuem para a performance de seu banco de dados: o sistema operacional, problemas de hardware (como memória e espaço em disco) e até o design do aplicativo que está acessando o banco de dados. O projeto de seu banco de dados também tem um papel importante na performance.
Neste artigo, falarei sobre alguns dos procedimentos que você pode adotar para melhorar a performance do banco de dados do SQL Server. Falarei especificamente sobre a capacidade do SQL Server 2000 de criar índices em Views e sobre como configurar apropriadamente seus índices usando o ITW (Index Tuning Wizard). Ensinarei o que fazer para garantir que suas consultas se beneficiem ao máximo das vantagens de informações de estatísticas e de índice.
A performance deve ser levada em conta desde a fase inicial do projeto do banco de dados. No entanto, você poderá fazer modificações para melhorá-la mesmo depois de ter iniciado a produção do banco de dados. Os índices são objetos de banco de dados que otimizam a busca e a classificação dos dados. Índices configurados apropriadamente podem fazer uma enorme diferença no tempo levado para inserir ou extrair dados do banco de dados. O ITW pode ajudá-lo a determinar como implementar índices no banco de dados para aumentar ao máximo a performance.
O ITW pode ser usado para recomendar a melhor configuração de índices para um banco de dados em função de uma carga de trabalho específica. Uma carga de trabalho é um script SQL ou rastreamento SQL que você salva em um arquivo externo.
As recomendações do ITW serão feitas de acordo com as cargas de trabalho e, por isso, é importante que você prepare antes as informações apropriadas. Provavelmente, a maneira mais fácil e completa de criar uma carga de trabalho para o ITW é salvar um rastreamento SQL criado pelo SQL Profiler. Um recurso novo do SQL Server 7.0, ele registra a atividade do servidor usando os filtros e critérios que você forneceu. Certifique-se de que seu rastreador SQL esteja registrando as atividades comuns do banco de dados quando criar um rastreamento com o SQL Profiler para ser usado com o ITW. Em outras palavras, escolha uma hora em que o banco de dados não esteja especialmente sobrecarregado ou subutilizado. O tempo que você levará para executar os rastreamentos dependerá especificamente do seu sistema. Em alguns casos, poderá levar apenas uma hora para executar o rastreamento e capturar uma representação precisa da atividade do sistema. Em outros, poderão ser necessários vários dias para registrar todas as variações padrão das atividades ocorridas no banco de dados.
Acione o ITW
Uma vez criado o arquivo de carga de trabalho a ser usado, acione o ITW selecionando um servidor na árvore no modo de visualização em árvore do Enterprise Manager. Selecione Wizards no menu Tools, abra o menu drop-down do nó Management na árvore de visualização e selecione Index Tuning Wizard. Será exibida a tela de boas-vindas do ITW. A segunda tela do ITW permite que você especifique qual servidor e banco de dados deseja analisar. Você tem duas opções adicionais nessa tela: Keep All Existing Indexes e Perform Thorough Analyses. Desmarcar a opção Keep All Existing Indexes permitirá que o ITW faça as recomendações de indexação. No entanto, o ITW pode sugerir a exclusão ou alteração de alguns dos índices existentes. Ou seja, se você não quiser alterar seus índices, deixe essa opção selecionada. Selecionar a opção Perform Thorough Analyses fará com que o ITW realize a análise mais completa e abrangente possível. Embora essa opção possa apresentar resultados melhores, provavelmente exigirá mais tempo para ser concluída. Além disso, ela também pode causar uma sobrecarga no servidor. Por esses motivos, se você escolher executar a análise completa, sugerimos que o faça em um servidor de teste ou, no caso de usar o seu servidor de produção, que a execute fora dos horários de pico.
A terceira tela do ITW pede que você especifique a carga de trabalho com a qual deseja trabalhar. Se estiver usando um arquivo criado pelo SQL Profiler, selecione o botão da opção My Workload File e use a caixa de diálogo File para localizar o arquivo em que salvou o rastreamento. Você também pode definir algumas opções avançadas nessa tela clicando no botão do comando Advanced Options. Essas opções incluem a especificação da quantidade máxima de espaço em disco a ser usada pelos índices recomendados e o número máximo de consultas no seu arquivo de carga de trabalho em que deverá ser feita a amostragem. Na quarta tela, você especifica as tabelas para as quais deseja receber recomendações de índice. A seleção de poucas tabelas poupará tempo e o ajudará a se concentrar nas áreas mais problemáticas.
No entanto, se estiver esperando que o ITW ofereça sugestões sobre como otimizar o banco de dados como um todo, você provavelmente escolherá selecionar todas as tabelas de seu banco de dados. A próxima tela do ITW mostra as recomendações de índice com base nos critérios que você forneceu (observe a Figura 1). Essa tela lhe oferece a opção de implementar imediatamente as recomendações (programando a execução para mais tarde) ou de salvar o script de execução em um arquivo externo.
Figura 1: Otimize com o ITW.
O ITW (Index Tuning Wizard) fornece as recomendações necessárias para que você configure os índices de seu banco de dados em função de um arquivo de carga de trabalho específico. Você pode implementar essas recomendações imediatamente ou agendá-las para serem executadas mais tarde. O SQL Profiler constitui uma ferramenta valiosa na criação dos arquivos de carga de trabalho que serão analisados pelo ITW.
O ITW não oferece recomendações sobre chaves primárias e outros índices exclusivos nem sobre índices para tabelas de sistema. Outras limitações incluem a incapacidade de rever mais de 37.767 consultas em uma carga de trabalho específica e a impossibilidade de oferecer sugestões para bancos de dados criados no SQL Server versões 6.5 e anteriores. Observe que o ITW faz as recomendações com base na análise de uma amostra de seus dados. Por esse motivo, você poderá perceber que está obtendo diferentes recomendações se executar o ITW mais de uma vez para a mesma carga de trabalho. Se o ITW não fornecer nenhuma recomendação, isto pode estar sendo causado por dois motivos: o ITW não está detectando nenhuma melhoria na performance da configuração do índice em relação à performance anterior ou não há dados de amostragem suficientes nas tabelas para que o programa arrisque uma recomendação apropriada.
Visualize os Índices
Além de indexar as tabelas, o SQL Server 2000 Enterprise Edition permite indexar Views. Suponha que você esteja interessado em analisar o total de unidades vendidas para cada pedido no banco de dados Pubs. Esse código SQL cria uma View denominada Quantity_Totals no banco de dados Pubs, que mostra as informações junto com uma contagem do número de itens contidos no pedido:
Listagem 1: Criando a View Quantity_Totals
Use Pubs GO CREATE VIEW Quantity_Totals with SCHEMABINDING AS SELECT ord_num, Total_Quantity = Sum(qty), Total_Items = Count_Big(*) FROM dbo.sales GROUP BY ord_num A função COUNT_BIG é n
A função COUNT_BIG é nova no SQL Server 2000 e funciona da mesma maneira que a função COUNT; a diferença reside no fato de que seu valor de retorno possui um tipo de dado bigint, ao contrário do tipo de dado int retornado pelo valor COUNT. Para que as Views que contiverem uma cláusula GROUP BY possam ser escolhidas para conter um índice, elas também deverão conter a função COUNT_BIG. Crie uma View que contenha um índice usando a opção SCHEMABINDING, que é nova no SQL Server 2000. Quando você especifica essa opção, a View é vinculada ao esquema de suas tabelas subjacentes.
Quando a View não contiver um índice, o resultset retornado não será armazenado permanentemente no banco de dados . Você até pode utilizar uma View que faça referência a muitas linhas de dados ou que envolva processamentos complexos, como a execução de agrupamentos agregados e de múltiplos joins, porém, o overhead exigido pelo SQL Server para recriar o resultset para o View a cada vez que ele for referenciado poderá ser significativo.
Os índices da View operam de forma bem parecida aos índices das tabelas. E, a exemplo destas, as Views também podem ter um índice em cluster e vários índices fora do cluster. No entanto, para criar índices fora de cluster, você precisará criar antes um índice em cluster exclusivo para a View. A criação de um índice em cluster para uma View armazena permanentemente no banco de dados o resultset referente a este modo. Embora os resultsets armazenados reflitam os dados do momento em que você criou o índice, todas as modificações feitas nos dados subjacentes serão atualizadas automaticamente no resultset. Para criar um índice em uma View, use a instrução CREATE INDEX (como se fosse criar um índice em uma tabela).
Listagem 2: Criando um índice usando CREAT INDEX
CREATE UNIQUE CLUSTERED INDEX PRIMARY_IDX on Quantity_Totals(ord_num)
Esse código cria um índice em cluster exclusivo para a View Quantity_Totals criado no exemplo anterior. Além de melhorar a performance das Views, a implementação de índices de Views também poderá resultar no aumento inesperado da performance geral. Quando você cria e armazena um índice para uma View no banco de dados, o Query Optimizer pode escolher usar esse índice para ajudar a melhorar a performance de outras consultas, inclusive daquelas que não fazem referência direta à View na cláusula FROM. Por exemplo, esta instrução SQL seleciona a soma de todas as quantidades agrupadas por número do pedido:
Listagem 3: Seleção da soma do agrupamento por numero do pedido
SELECT ord_num, Sum(qty) FROM sales GROUP BY ord_num
Quando esse código é executado, o Query Optimizer percebe que a soma das quantidades já existe no índice criado anteriormente pelo SQL Server para a View Quantiy_Totals. Nesse caso, ele pode determinar se o uso do índice criado para a View resultará na execução mais eficaz dessa consulta. Você deverá atender a vários termos e condições antes de tentar adicionar índices a Views (consulte a Tabela 1).
Tabela 1: Prepare-se para trabalhar com índices em Views. Você precisa respeitar algumas condições ao criar um índice em uma View. A lista a seguir descreve algumas delas.
| Elemento | Condição |
| Criar View | Você precisa criar a View com a opção SCHEMABINDING. Além disso, as opções ANSI_NULLS e QUOTED_IDENTIFIER deverão estar ativadas (ON) quando você criar a View. |
| Fazer referência a tabelas por View | Não é possível fazer referências a tabelas localizadas em diferentes bancos de dados na View. Para criar tabelas que sejam referenciadas por Views, você precisa definir a opção ANSI_NULLS como ON. A View só faz referência a tabelas base, e não a outros tipos de Views. |
| SQL contido na View | A instrução SELECT na View não pode conter o operador UNION nem nenhuma subconsulta. Também não pode conter as palavras-chave DISTINCT ou ORDER BY, nem as funções MIN, MAX ou AVG. Você deve fazer referências explícitas às colunas. A instrução SELECT não pode usar * nem table_name.* para fazer referências às colunas. |
Ajuste suas Consultas
Além do projeto físico do banco de dados, a estrutura das consultas que você usa para salvar e recuperar dados também pode causar um impacto significativo na performance. Problemas de hardware, como memória e espaço em disco insuficientes, podem contribuir para retardar as consultas. Contudo, a má performance nas consultas pode indicar que o Query Optimizer não consegue aproveitar satisfatoriamente as vantagens das informações de estatísticas e índices.
As informações de estatísticas consistem em informações sobre a distribuição dos dados em uma coluna. O Query Otimizer usa essas informações para ajudar a determinar a melhor maneira de executar uma consulta. Quando você cria um índice em uma coluna, o SQL Server cria automaticamente as informações de estatísticas para as colunas do índice. Por padrão, a opção do banco de dados Auto Create Statistics no SQL Server é definida como um valor True. Isso faz com que o SQL Server também crie automaticamente informações de estatísticas nas colunas adicionais de sua tabela. Além de criar informações de estatísticas, o SQL Server atualiza constantemente essas informações.
A freqüência com que ele atualizará essas informações dependerá da freqüência com que os dados forem alterados nas colunas ou no índice, bem como do volume de dados contido nessas colunas. De modo geral, o SQL Server faz um trabalho eficiente de criação e atualização de informações de estatísticas nas tabelas sem qualquer intervenção manual, porém, às vezes você poderá achar que as informações são insuficientes ou que não foram atualizadas na freqüência que deveriam.
Você pode usar o comando DBCC SHOW_STATISTICS Transact-SQL (T-SQL) para ver as informações existentes no momento atual para as colunas de um índice. Esse comando utiliza dois parâmetros. O primeiro corresponde ao nome da tabela cujas informações você deseja visualizar, e o segundo é nome do índice. A execução desta linha do SQL no Query Analyser mostra as informações de estatísticas disponíveis para um índice na tabela de autores do banco de dados Pubs, denominado aunmind:
Listagem 4: Comando para vizualizar colunas de um índice
DBCC SHOW_STATISTICS (authors, aunmind)
As informações retornadas pelo comando DBCCSHOW_STATISTICS incluem a data e hora em que o SQL Server atualizou pela última vez as informações de estatísticas, bem como o número de linhas usadas na amostragem.
O Query Analyzer também pode ser usado para visualizar graficamente informações de colunas que não façam parte de um índice. Para fazer isso, abra o Query Analyser e selecione Manage Statistics no menu Tools. Na caixa de diálogo Manage Statistics, selecione o banco de dados e a tabela ou View (modo de exibição) para as informações que deseja gerenciar (observe a Figura 2).
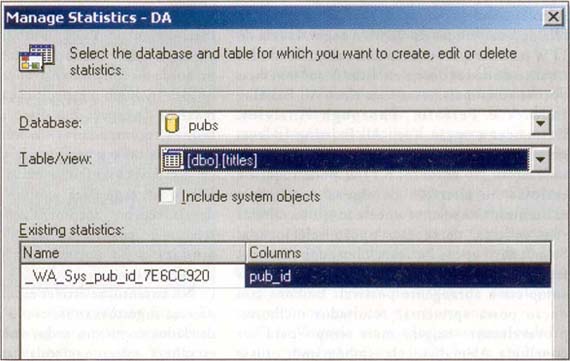
Figura 2: Trabalhe com Informações de Estatísticas.
Você pode abrir a caixa de diálogo Manage Statistics a partir do Query Analyzer. Nessa caixa, você poderá criar, editar e excluir estatísticas por intermédio de uma interface gráfica.
O programa preencherá todas as estatísticas existentes na caixa de listagem na parte inferior da tela. Para modificar ou remover informações referentes a uma estatística existente, selecione a estatística e clique em um dos botões de comando Update ou Delete. Caso deseje criar uma nova estatística, clique no botão New para abrir a caixa de diálogo Create Statistics. Ao criar a nova estatística, você terá oportunidade de selecionar as colunas a serem incluídas, a porcentagem dos dados a ser usada como amostragem pelo SQL Server para criar as informações de estatísticas e se deseja que o SQL Server atualize essas estatísticas automaticamente sempre que for necessário.
É uma boa idéia permitir que o SQL Server faça as atualizações automaticamente, já que o programa fará um trabalho eficiente e a atualização manual pode se tornar uma tarefa bastante enfadonha. Além de criar e atualizar estatísticas com a interface gráfica fornecida pelo Query Analyser, você também poderá criar ou atualizar estatísticas por meio dos comandos CREATE STATISTICS e UPDATE STATISTICS T-SQL.
Visualizar o Plano de Execução
Uma maneira de determinar se uma dada consulta está aproveitando ao máximo as vantagens dos índices e informações de estatísticas é visualizar o plano de execução dessa consulta no Query Analyser. Para fazer isto, abra o Query Analiser e carregue a consulta. Selecione Show Execution Plan no menu Query e execute a consulta.
Abaixo dos resultados da consulta, você verá a guia Execution Plan. Clique nesta guia para visualizar o plano de execução para a consulta. Você também pode ver um plano de execução projetado sem precisar efetivamente executar a consulta. Selecione Display Expected Execution Plan no menu Query para criar um diagrama que mostra o plano de execução estimado para a consulta. Esse diagrama mostra as etapas que o Query Optimizer usou (ou usará) para executar a consulta.
Ao analisar os detalhes de cada etapa, você poderá identificar quais etapas levaram mais tempo e quais demandaram mais recursos. Você também poderá ver se o Query Optimizer está usando os índices. Sempre que encontrar uma tabela com informações insuficientes ou desatualizadas, o Query Optimizer mostrará a legenda dessa tabela em vermelho.
Arraste o mouse sobre o diagrama da tabela para ver mais informações sobre as etapas em uma janela pop-up (observe a Figura 3). A ferramenta SQL Profiler é excelente para ajudá-lo a identificar as consultas que causam problemas na performance e que precisam ser analisadas de forma mais aprofundada. O SQL Profiler pode identificar consultas lentas e instruções SQL por meio do registro das atividades específicas ao seu servidor.

