
Banco de Dados - MySQL
Índices MySQL : Otimização de consultas
Veja neste artigo como otimizar consultas no banco de dados MySQL através da utilização de índices. Serão apresentadas ainda algumas dicas gerais para melhorar a performance das consultas a tabelas com grandes volumes de dados.
por Joel RodriguesIntrodução aos Índices MySQL
Quando se trabalha com bancos de dados, diariamente é preciso fazer consultas a tabelas com grandes quantidades de registros e que por este motivo levam algum tempo para serem lidas para que o resultado seja retornado. Independente da plataforma (desktop, web, mobile), o desempenho das aplicações é um fator fundamental e determinante, por exemplo, quando um cliente vai adquirir um sistema. Por isso, os programadores e administradores de bancos de dados se esforçam para que o tempo de resposta, quando consultas a bancos de dados são feitas, seja o menor possível.
Diante dessas situações, vários métodos podem garantir melhoria nesse tempo de resposta. A seguir são apresentadas algumas dicas que, apesar de simples, podem aumentar o desempenho de consultas, principalmente àquelas tabelas com grandes muitos dados armazenados.
- Ao realizar uma consulta, selecione apenas as colunas realmente necessárias, isso reduz a quantidade de dados retornada. Nem sempre é preciso usar o “SELECT *”, então vale a pena avaliar quais campos serão realmente utilizados e listá-los na cláusula select.
- Na cláusula where, procure usar sempre a seguinte ordem nos filtros pelo tipo da coluna: NUMÉRICOS -> DATA/HORA -> TEXTO SIMPLES -> TEXTO EXTENSOS/BINÁRIOS. Essa ordem se explica pelo nível de exatidão e complexidade de cada tipo de dado. Quanto mais exato e menos complexo for o dado da coluna, mais simples é a avaliação do seu valor.
- Sempre que possível utilize consultas por igualdade no lugar de filtros por faixas de valores, isso reduz a quantidade de avaliações feitas com o valor (se possível, dê prioridade a filtrar pelos dados na ordem da dica anterior).
- Considere utilizar índices, principalmente em campos numéricos de suas tabelas. Essa medida ajuda o gerenciador do banco de dados a localizar os registros com mais facilidade. Esse elemento (índice) é o principal foco deste artigo e será melhor explicado a seguir.
Entendo os índices
Antes de falarmos diretamente sobre os índices, é preciso que tenhamos entendido como funcionam as consultas tradicionais nos bancos de dados.
Quando temos uma tabela e executamos uma operação de SELECT sobre ela, filtrando por um ou vários campos, o gerenciador do banco efetua uma ação chamada “TABLE SCAN”. Essa ação consiste em percorrer toda a tabela, avaliando cada registro. Caso o registro atenda às condições definidas no filtro, ele é incluído no conjunto de retorno, senão, é apenas desconsiderado.
A figura a seguir ilustra uma pesquisa desse tipo, filtrando uma tabela pelo campo “Codigo”, onde seu valor seja “3”.
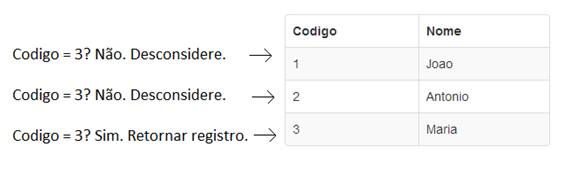
Figura 1: Esquema de consulta Table Scan
No exemplo acima a tabela continha apenas três registros e a consulta foi facilmente concluída, porém, imagine algo semelhante em uma tabela com milhares de linhas.
Para melhorar essas consultas, utilizamos ÍNDICES, objetos do banco de dados que facilitam a organização e consulta de uma tabela, “indexando-a” por uma de suas colunas.
Quando criamos um índice em uma coluna, o gerenciador do banco ordena a tabela por essa coluna e a partir de então os filtros (sobre essa coluna) são feitos através de uma busca binária.
Na busca binária, a tabela sofre divisões sucessivas até que o registro desejado seja localizado. Inicialmente a tabela é “dividida” na metade, onde os registros com os menores valores no campo indexado ficam na parte superior, e os registros com os maiores valores ficam na parte inferior. O gerenciador verifica então em que parte está contido o valor pesquisado, se na primeira metade ou na segunda. Isso é facilmente feito comparando o valor pesquisado com o do registro intermediário. Se o valor pesquisado for maior que o do registro intermediário, o registro desejado encontra-se na segunda metade, caso contrário, encontra-se na primeira metade. Na figura a seguir temos uma ilustração desse processo.
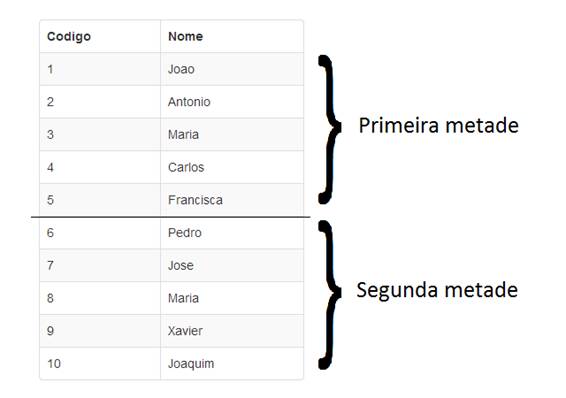
Figura 2: Divisão da tabela na metade
Por exemplo, se pesquisássemos pelo registro de Codigo = 3, seria avaliado se esse valor é maior ou menor que 5. Como o valor é menor, indica que o registro procurado encontra-se na primeira metade.
Em seguida, o processo é repetido apenas na metade em que se encontra o registro pesquisado, dividindo-a na metade e avaliando novamente em que parte encontra-se o que se deseja.
Note que na operação de table scan, todos os registros seriam lidos e com a utilização de índices, na primeira divisão já se descarta metade dos registros da tabela. Para tabelas pequenas a diferença dificilmente é percebida, mas quando se trabalha com grandes volumes de dados, essa simples mudança pode evitar, por exemplo, um erro de “time out” (tempo de máximo de requisição excedido).
Observação: esse modelo de busca se baseia na árvore de busca binária, estrutura de dados e consulta largamente utilizada na computação.
Índice no MySQL
No banco de dados MySQL os índices podem ser criados com considerável facilidade, tanto no momento da concepção da tabela quanto em uma tabela já existente.
Mantendo os exemplos que foram dados anteriormente, vamos criar uma tabela chamada CLIENTES com dois campos: Codigo, do tipo inteiro e Nome do tipo texto.
Primeiramente veremos como criar o índice junto com a tabela, na Listagem 1.
Listagem 1: Criando o índice junto com a tabela
CREATE TABLE CLIENTES ( Codigo INT, Nome VARCHAR(50), INDEX (Codigo) );
O índice é criado com o uso da palavra reservada INDEX, seguida do nome da(s) coluna(s) a ser(em) indexada(s).
Porém, nem sempre sabemos onde vamos precisar de um índice e muitas vezes é preciso criá-los quando a tabela já existe e inclusive quando já possui registros. Isso pode ser feito com uma instrução DDL (Data Definition Language), como veremos a seguir. Inicialmente criamos a tabela sem índice algum, em seguida adicionamos o índice à coluna “Codigo”.
Listagem 2: Criando a tabela sem índices
CREATE TABLE CLIENTES ( Codigo INT, Nome VARCHAR(50 );
Em seguida, para criar o índice usamos a instrução CREATE.
Listagem 3: Criando o índice separadamente
CREATE INDEX idx_CLIENTES_CODIGO ON CLIENTES(Codigo);
Nesse caso precisamos definir um nome para o índice (por questão de padronização, alguns profissionais optam por iniciar o nome do índice com um prefixo que indique que ele é um índice, como “id” ou “idx” de “index”, em inglês).
Após o nome do índice adicionamos a palavra reservada “ON” que indica em que tabela e coluna o índice será criado, dados que vêm logo em seguida, como vemos na listagem.
Conclusão
Em um contexto (pode-se dizer mundial) onde a quantidade de dados armazenados virtualmente só aumenta, o rápido acesso a eles é de extrema importância, pois o excesso de tempo gasto em uma operação pode, inclusive, acarretar prejuízos.
O uso de índices e de técnicas de otimização, como as que foram citadas no início desse artigo, garante o ganho de performance nas consultas a bancos de dados e, consequentemente, nas aplicações que os acessam.
Espero que tenham gostado das informações aqui apresentadas e que essas possam ser úteis. Até a próxima oportunidade.

