
Banco de Dados - DB2
DB2 - Subqueries Correlacionadas
Antes de falarmos das subqueries correlacionadas, vamos falar como o DB2 trata uma subquerie não-correlacionada. Quando o DB2 encontra uma subquerie não-correlacionada ele executa a subquerie e passa os valores obtidos para a querie externa...
por Milton GoyaAntes de falarmos das subqueries correlacionadas, vamos falar como o DB2 trata uma subquerie não-correlacionada. Quando o DB2 encontra uma subquerie não-correlacionada ele executa a subquerie e passa os valores obtidos para a querie externa. Esta passa a extrair as linhas que atendem o resultado da subquerie. A subquerie é executada apenas uma vez e o custo de execução é relativamente barato, não importando quantas linhas sejam lidas.
A subquerie correlacionada tende a ter performance inferior a de uma subquerie não-correlacionada. Vamos examinar uma subquerie correlacionada:
Listagem 1:
SELECT empno, ename, deptno, sal
FROM emp e
WHERE sal>
(SELECT AVG (sal)
FROM emp
WHERE deptno = e.deptno)
Onde:
- Empno - Código do empregado
- Ename - Nome do empregado
- Deptno - Código do departamento
- Sal - Salário
- Emp - Tabela de Empregados
Uma subquerie é dita correlacionada quando a querie executa várias vezes a subquerie. No caso do exemplo acima, uma única linha da tabela EMP é lida pela querie externa e o valor dos campos EMPNO, ENAME, DEPTNO e SAL são determinados para esta linha. Uma vez feito isso, o valor do campo DEPTNO é passado para a subquerie e ela irá usar esse valor para calcular a média salarial de todas as pessoas desse departamento.
O valor obtido pela subquerie é devolvido para a querie externa que irá comparar o salário obtido anteriormente com a média salarial determinada pela subquerie. Caso o salário for maior que a média salarial então esta linha será mostrada no resultado final, caso contrário será desprezada. Esse procedimento será repetido para cada linha até toda a tabela ter sido examinada. Caso a tabela EMP tiver um milhão de linhas então a subquerie será executada um milhão de vezes.
O processo pode ser resumido pelo gráfico abaixo:
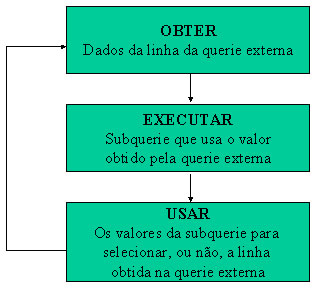
Figura 1: Gráfico
Subqueries Correlacionadas - as subqueries correlacionadas são usadas para processamento por linha. Cada subquerie é executa uma vez para cada linha da consulta externa.
Devido a essa característica da subquerie correlacionada o OPTIMIZER do DB2 trabalha de uma maneira diferenciada quando encontra esse tipo situação. Ele salva os resultados intermediários da subquerie em uma área de trabalho temporária.
No nosso exemplo, a média de salário de cada departamento é salva na área de trabalho temporária na primeira vez em que a média do departamento for calculada. Quando a querie externa encontra uma linha com o mesmo valor de correlação da área de trabalho temporária o DB2 utiliza o valor previamente calculado. Isso elimina a necessidade de recalcular a média salarial para os departamentos que já foram pesquisados. No caso de uma tabela hipotética com um milhão de registros e duzentos departamentos o OPTIMIZER do DB2 irá executar a subquerie apenas duzentas vezes e nas demais consultas pegará o valor diretamente da área de trabalho temporária, o que faz com que a performance da subquerie relacionada seja bem melhor do que a do caso descrito anteriormente.
As subqueries correlacionadas podem ser usadas para atualizar tabelas. Vejamos um exemplo:
Listagem 2:
ALTER TABLE emp
ADD (dname VARCHAR (30))
UPDATE emp e
SET dname =
(SELECT dname
FROM dept d
WHERE e.deptno = d.deptno)
Onde:
- Deptno - Código do Departamento
- Dname - Nome do Departamento
- Emp - Tabela de Empregados
- Dept - Tabela de Departamentos
No nosso exemplo estamos incluindo a coluna DNAME na tabela EMP e estamos usando uma querie correlacionada para preencher o nome dos departamentos a partir dos dados da tabela de departamentos (DEPT). Através do mesmo raciocínio também podemos eliminar linhas da tabela.
Muitas vezes podemos substituir a subquerie correlacionada por tabelas aninhadas. Por exemplo:
Listagem 3:
SELECT empno, ename, e.deptno, sal
FROM emp e
INNER JOIN
(SELECT deptno, AVG (sal) AS media_sal
FROM emp
GROUP BY deptno) AS m
ON e.deptno = m.deptno
WHERE sal> media_sal
Esta outra sintaxe produz o mesmo resultado da querie correlacionada, mas sem precisar usar a área de trabalho intermediária. Graças a esse detalhe, a performance dessa sintaxe é melhor do que a da querie correlacionada.
Fontes:
Database Administration Certification Guide. George Baklarz e Bill Wong

