
Desenvolvimento - XML
O uso do XML na integração de Banco de Dados Relacionais
Este artigo visa mostrar como se pode utilizar o padrão XML na integração de Dados de Bancos Relacionais.
por Eduardo Feltrin MarquesObs: Este artigo faz parte do projeto de conclusão de curso de Sistemas de Informação do autor.
Eduardo Feltrin Marques Aglaê Pereira Zaupa
Universidade do Oeste Paulista (UNOESTE)-
FIPP (Faculdade de Informática de Presidente Prudente)
feltrin@fipp.unoeste.br aglae@unoeste.br
RESUMO. A necessidade da troca de dados advindos de diferentes fontes vêem crescendo relativamente, justamente pelo grande tráfego de informação que é gerado tanto em sistemas convencionais como web. Tais dados, usualmente gerados por pessoas, são escritos de várias maneiras, sendo que, em alguns casos, um mesmo objeto do mundo real pode ser representado de várias formas. O objetivo da integração de dados é permitir o acesso integrado a várias fontes de informação heterogêneas e independentes, através de uma visão global.
Com a especificação do padrão XML, o mesmo passou a ser utilizado para intercâmbio de dados, uma vez que é capaz de agregar a seu conteúdo informações que o descrevem(metadados), possibilitando assim a representação de dados que não poderiam ser representadas através do modelo relacional utilizado pela maioria dos SGBDs. Com o padrão XML é possível então a criação de visões materializadas dos dados armazenados em um SGBD local e utilizar esta visão para os mais variados fins, por isso o XML (eXtensible Markup Language) vem se caracterizando como um padrão de troca e integração de dados, de forma que, os sistemas de integração de dados a têm utilizado como modelo comum.
Este artigo visa mostrar como se pode utilizar o padrão XML na integração de Dados de Bancos Relacionais
1- INTRODUÇÃO
A XML (eXtensible Markup Language, ou Linguagem Extensível de Marcação) foi criada em 1996, por especialistas do World Wide Web Consortium (W3C), órgão de regulamentação dos padrões utilizados na internet. Ela fornece um formato estruturado para descrição de dados e foi criada como um subconjunto simplificado do padrão SGML (Standard Generalized Markup Language, ou Linguagem Padrão de Marcação Generalizada).
Características de flexibilidade e portabilidade vêm fazendo com que, nos últimos anos, a XML seja aceita como um padrão para representação, intercâmbio e manipulação de dados em aplicações para as mais diversas áreas de negócios. Representação de dados em aplicações de gerenciamento de conteúdo, aplicações de transações bancárias e de publicação de conteúdo em intranets são alguns exemplos de uso da XML.
O crescimento na utilização da XML levou a um aumento significativo no volume de dados nesse formato que são armazenados, transportados e recuperados por aplicações no mundo todo. Um exemplo que ilustra essa nova demanda é a troca de dados entre dois sistemas de bancos de dados diferentes, usando documentos XML para o intercâmbio dos dados.
Essa nova realidade faz surgir novos questionamentos a respeito de onde e como armazenar esses dados, e qual a melhor maneira de integrar as tecnologias já existentes de sistemas de bancos de dados (principalmente no modelo relacional) com a XML. Também surgiram novas tecnologias para armazenamento de XML a serem consideradas, como os bancos de dados nativos de XML.
Esse trabalho de pesquisa apresenta um panorama das formas mais adotadas atualmente para a integração de dados de diversas bases relacionais em um mesmo local no formato XML.
O capítulo 2 traz um breve histórico da XML, a definição do que é a XML, e expõe alguns conceitos básicos sobre ela.
O capítulo 3 mostra algumas técnicas de integração de dados de diversas bases relacionais em um documento XML.
2- XML
O XML é uma linguagem derivada da SGML e foi idealizada por Jon Bosak, engenheiro da Sun Microsystems. O autor era conhecedor e usuário de SGML e apresentou ao W3Consortium, sua idéia de explorar o SGML em aplicações voltadas para internet. Em 1996 foi criado o XML, inicialmente como uma versão simplificada da SGML e em fevereiro de 1998, o XML tornou-se uma especificação formal, reconhecida pela W3C.
Segundo a W3 Consortium, dados semi-estruturados são dados dispostos em representações rígidas, sujeitas a regras e a restrições impostas pelo esquema que os criou. Programas que produzem tais dados os armazenam em disco, para que possam ser utilizados em formato binário ou texto.
Os dados semi-estruturados representam hoje um componente importante de ambientes heterogêneos como a internet e o padrão XML, por permitir a criação de uma marcação flexível, aceita bem variações na estrutura características desse tipo de dado.
Tabela 1 – Exemplo de um texto livre e o seu correspondente XML
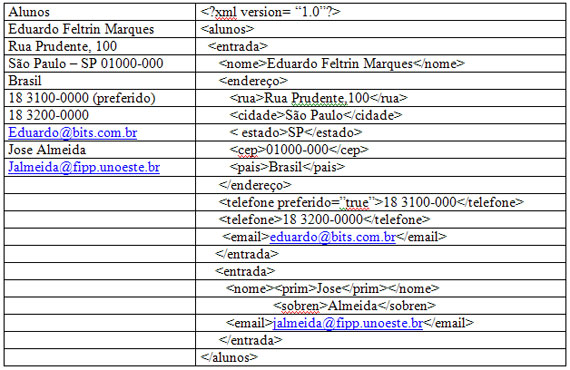
2.1 - Documentos XML
Um documento XML é um texto (em
formato Unicode) com tags de marcação (markup tags) e outras informações. Os documentos
XML são sensíveis à letras maiúsculas e minúsculas. Um documento XML é bem formatado
quando segue algumas regras básicas. Tais regras são mais simples do que para documentos
HTML e permitem que os dados sejam lidos e expostos sem nenhuma descrição externa
ou conhecimento do sentido dos dados XML. Documentos bem estruturados:
-
tem casamentos das
tags de início e fim
- as tags de elemento tem que ser apropriadamente posicionadas
Existem 6 tipos de itens de marcação que podem ocorrer no XML:
-
Elementos
- Referências a entidades
- Comentários
- Instruções de processamento
- Seções marcadas
- Tipos de documentos
Elementos : São a mais comum forma de marcação. Delimitados pelos sinais de menor e maior, a maioria dos elementos identificam a natureza do conteúdo que envolvem, alguns elementos podem ser vazios, neste caso eles não têm conteúdo.
Referências a Entidades: A fim de introduzir a marcação em um documento,
alguns documentos foram reservados para identificar o início da marcação. O sinal
de menor, < por exemplo, identifica o início de uma marca de inicio ou término.
Em XML, entidades são usadas para representar estes caracteres especiais. As entidades
também são usadas para referenciar um texto freqüentemente repetido ou alterado
e incluí-lo no conteúdo de arquivos externos. Cada entidade deve ter um nome único.
Comentários: Comentários iniciam com <!-- e terminam com -->.
Os comentários podem conter qualquer dado, exceto a literal "--". Você pode colocar
comentários entre marcas em qualquer lugar em seu documento. Comentários não fazem
parte de um conteúdo textual de um documento XML. Um processador XML não é preciso
para reconhecê-los na aplicação.
Instruções de Processamento: Instruções de processamento (PIs)
são formas de fornecer informações a uma aplicação. Assim como os comentários, elas
não são textualmente parte de um documento XML, mas o processador XML é necessário
para reconhecê-las na aplicação.
Seções Marcadas: Em um documento, uma seção CDATA instrui o analisador
para ignorar a maioria dos caracteres de marcação. Considere um código-fonte em
um documento XML. Ele pode conter caracteres que o analisador XML iria normalmente
reconhecer como marcação (< e &, por exemplo). Para prevenir isto, uma seção
CDATA pode ser usada.
2.1.1 -
Documentos Bem-formados
São documentos que atendem à sintaxe XML usada dentro do documento. Por exemplo, em casos de não incluir marcas de fechamento ao inserir elementos no documento, esquecer de incluir a declaração de documento XML no início do documento, se incluir caracteres que não possam ser analisados sintaticamente ou sejam inválidos, você não possuirá um documento XML bem-formado.
Documentos bem-formados são na
realidade, mais do que simples documentos que seguem a sintaxe XML. Além disso,
os considerados bem-formados devem atender às seguintes condições:
-
Nenhum atributo pode
aparecer mais do que uma vez em uma única marca de início;
- Não pode incluir referências a entidades externas em um atributo de string;
- Deve-se declarar todas as entidades exceto aquelas incluídas como parte da linguagem XML;
- Não pode se referir a uma entidade binária no corpo do conteúdo;
- Não pode criar entidades de texto ou de parâmetros recursivas seja direta, seja indiretamente;
- As entidades paramétricas devem ser declaradas antes para que se possam usá-las em um documento;
- Quaisquer marcas não - vazias devem ser aninhadas adequadamente;
- O nome na marca de fim de um elemento deve coincidir com o tipo de elemento da marca de início;
- Não podemos incluir um (<) no texto substitutivo de qualquer entidade;
2.1.2 - Documentos Válidos
Um documento bem-formado não é válido a menos que ele contenha uma DTD apropriada.
O documento também precisa obedecer as restrições dessa declaração.
-
Uma descrição das regras estruturais que o
documento deve seguir;
- Uma lista de recursos externos ou entidades externas que criem qualquer para específica do documento;
- Quaisquer declarações dos recursos internos ou entidades internas;
- Quaisquer notações ou recursos não-XML que devem ser enumerados no documento;
- Listas de qualquer recurso não-XML que possam ser encontradas no documento.
2.2 – Linguagens de definição de esquemas
Algumas abordagens para definição de estruturas para documentos XML bastantes conhecidas são DTD (Document Type Definition) e XML Schema.
2.2.1 – DTD
Comumente, atribui-se à uma DTD a responsabilidade do uso de uma linguagem oficial
para delimitar a estrutura e os possíveis valores nos documentos XML. Basicamente
uma DTD define um vocabulário comum que documentos xml referenciados devem obedecer.
Complexo é um tipo que define a estrutura de um elemento, características dos sub-elementos, atributos, cardinalidade dos sub-elementos e obrigatoriedade dos atributos.
3- INTEGRAÇÃO DE DADOS
Um dos principais requisitos para a integração de sistemas de informações é a existência de um mecanismo que possa mediar e compatibilizar a troca de informações entre sistemas que utilizam diferentes formas de representações. As novas tecnologias associadas a linguagem Extensible Markup Language (XML) possibilitam o desenvolvimento de estruturas de mediação que atendem a este requisito. Integrar diversas fontes heterogêneas de dados é um desafio que a anos vem fomentando pesquisas e surgimento de novos padrões a fim de tornar transparente o acesso a estas fontes para os usuários e desenvolvedores de aplicações [Fer02].
Este artigo tem a finalidade de mostrar uma técnica usada para integrar diversas bases de dados relacionais em uma única base XML.
Para realizar tal operação é necessária a utilização de uma técnica apropriada que faça essa integração de dados de tal forma que não seja perdida ou deixada de lado nenhuma informação relevante contida em qualquer uma das bases de dados que serão integradas.
3.1 – CASAMENTO DE ESQUEMAS
A tarefa de casar esquemas, independentemente da técnica utilizada, pode ser vista como uma generalização de uma operação fundamental, chamada casamento (Match). Essa operação recebe como argumentos dois esquemas e produz um conjunto de casamentos entre elementos desses esquemas. Considerando-se, por exemplo, a existência de dois esquemas, S e T, sendo S composto por um conjunto de elementos s1, s2.....sn e T composto por t1, t2.....tn, um casamento s1 ? t1 é um valor que indica o grau de similaridade entre esses dois elementos. Normalmente este valor está contido no intervalo [0; 1], onde 1 representa o maior grau de similaridade possível. As informações nesta seção foram retiradas de [Mer07].
Para efeitos de classificação, considera-se que o casamento pode ser implementado
de diferentes maneiras, envolvendo o uso de um conjunto de algoritmos de casamento
ou casadores (matchers). A forma como os algoritmos são utilizados permite imaginar
a solução do problema em dois níveis. No primeiro, são considerados os casadores
individuais, ou seja, apenas um algoritmo é aplicado. No segundo, diversos algoritmos
individuais são combinados, pelo uso de uma das seguintes alternativas:
Instância versus esquema: as abordagens de casamento podem considerar dados das instâncias ou somente dos esquemas;
O processo de casamento de esquemas possui duas funções importantes, uma é definir
como os esquemas a serem casados interagem com os algoritmos de casamento e a outra
é estabelecer critérios a serem usados no processo de casamento propriamente dito.
A figura 9 mostra a visão geral do processo de casamento.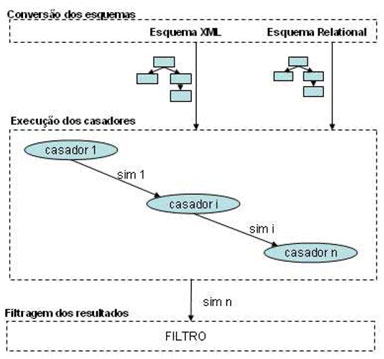
Figura 9 – Visão Geral do Processo de Casamento
O processo de casamento de esquema é dividido em três etapas:
i
Os esquemas XML e relacional são representados nesta técnica como grafos acíclicos.
Os casadores usam estes grafos para realizar as comparações entre os nós de ambas
as representações. A Figura 10 mostra a descrição de um esquema relacional, juntamente
com o grafo gerado para ele.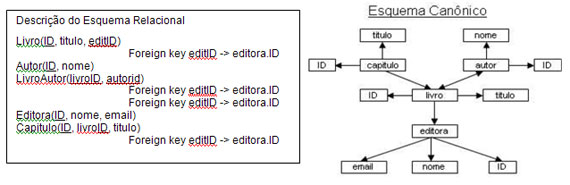
Figura 10 – Esquema Canonico Relacional
A Figura 11 mostra a descrição de um esquema xml, juntamente com o grafo gerado para ele.
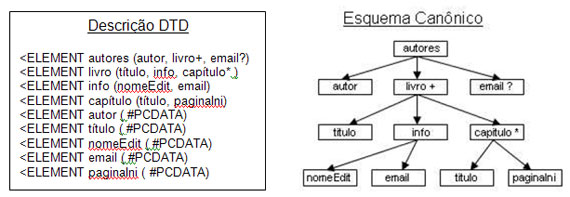
Figura 11 – Esquema Canonico XML
3.1.1 – TÉCNICAS DE CASAMENTO LINGÜISTICO
Um casador lingüístico possui um algoritmo de reconhecimento dos caracteres em comum entre duas cadeias, e uma métrica que permite computar a similaridade com base nos caracteres em comum.
A técnica apresentada para o casamento lingüístico visa combater uma deficiência encontrada nas demais técnicas existentes. Essa deficiência advém de casos onde as cadeias comparadas são compostas por termos, e a maior diferença entre elas é a ordem em que os seus termos aparecem. Além disso, os termos em cada cadeia não são separados por espaços em branco. Esse tipo de cadeia pode ser encontrado tanto em esquemas XML como em esquemas relacionais. Em ambos os esquemas, os nomes dos conceitos não podem conter espaços em branco.
Existem técnicas que possibilitam inferir a similaridade entre duas cadeias verificando os termos que elas têm em comum, onde um termo é uma seqüência de caracteres adjacentes. São as técnicas baseadas em termos. Sabendo quais são os termos das duas cadeias, podem-se utilizar diversas métricas que computem a similaridade com base nos termos em comum (Dice, Ledit, Overlap, Jaccard, ...). Nessas técnicas, a identificação dos termos é trivial: cada conjunto de caracteres separado por espaço - ou seja - uma palavra - é um termo.
A métrica a ser utilizada deve ser baseada em termos, uma vez que o objetivo do algoritmo é fornecer termos em comum entre duas cadeias. No entanto, as métricas existentes apresentam problemas quando aplicadas ao problema em questão, principalmente pela forma como os termos são formados.
Convém ressaltar que podem existir
mais formas de determinar como os nomes dos elementos XML são formados a partir
de um esquema relacional. O estudo sobre formas alternativas de nomenclatura pode
ser alvo de trabalhos futuros. Dado um par de elementos que se deseja casar, verifica-se
a ocorrência de um dos três padrões de nomenclatura expostos acima. Essa verificação
envolve o uso de técnicas de casamento lingüístico que retornam um valor de similaridade
para cada um dos padrões analisados. O padrão com o maior valor de similaridade
é escolhido vencedor, e esse valor de similaridade é atribuído ao par dos elementos
casados.
Assim, para tornar o algoritmo
de casamento aqui descrito genérico, admite-se que várias técnicas lingüísticas
possam ser aplicadas. O agrupamento dos resultados de cada técnica pode seguir duas
abordagens distintas: a abordagem otimista e a pessimista: Na abordagem otimista,
o maior valor de similaridade entre as técnicas é escolhido, e os demais são descartados.
Esta abordagem é considerada otimista, pois ela procura maximizar o valor de similaridade.
Já na abordagem pessimista o menor valor de similaridade entre as técnicas é escolhido.
A principal
diferença entre as abordagens otimista e pessimista é que com o uso da primeira
alternativa os casamentos possuem graus de similaridade sempre maiores, ou pelo
menos iguais, aos casamentos obtidos com o uso da segunda alternativa. Uma conseqüência
disso é que a primeira abordagem tende a apresentar similaridades altas para casamentos
incorretos. Por outro lado, a abordagem otimista pode descartar casamentos corretos
que não atingiram um valor alto de similaridade.
3.1.2.2 – CASADOR DE RELAÇÃO
Este casador estrutural faz parte de um trabalho inicial na exploração das estruturas
dos esquemas para a inferência de similaridades nos nós atômicos. Este casador utiliza
a noção de nós relacionados: todo nó atômico
ni
possui um conjunto não vazio de nós relacionados. Os nós relacionados
à ni são todos aqueles
que são direta ou indiretamente conectados a ele.
Este casador parte da suposição de que a similaridade entre um par (ni;
nj)
é proporcional à similaridade entre os nós relacionados de
ni
e os nós relacionados de nj.
O cálculo da similaridade é efetuado usando uma técnica de casamento lingüístico,
podendo ser a citada acima.
Como este casador não analisa as propriedades dos nós atômicos propriamente ditos,
em alguns casos podem ocorrer conflitos na análise. Porém, esses efeitos são previsíveis
e até mesmo esperados. Recomenda-se que este casador não seja usado de forma isolada,
mas em combinação com outro(s) casador(es), principalmente casador(es) que analise(m)
as propriedades dos nós atômicos.
3.1.2.3 – CASADORES DE ATRAÇÃO
O conceito
de atração considera que para todo par de nós casados, sendo cada um deles provenientes
de um esquema, são gerados dois campos de atração, um em cada esquema. Todos os
nós contidos em cada campo são chamados de nós internos, Os nós que geraram os campos
de atração são chamados de nós origem.
Os campos de atração atuam no sentido de atribuir similaridades entre os nós internos
de um campo e os nós internos do outro campo. Em outras palavras, parte-se da suposição
de que os nós internos possuem um grau de similaridade entre si semelhante à similaridade
dos nós que geraram os campos. Cada campo de atração possui uma intensidade, que
é equivalente às similaridades dos nós origem. Ou seja, quanto maior for a similaridade
entre os nós origem, maior é a intensidade do campo. Considera-se que essa similaridade
já tenha sido computada por um outro casador.
Casadores de atração pode se dividir em Casador de Vizinhança (atribui valores de
similaridade considerando a noção de vizinhança entre os nós) e Casador de Cardinalidade
(atribuem valores de similaridade considerando a noção de dependência multivalorada
entre os nós)
3.1.3 – IMPLEMENTAÇÃO DOS CASADORES ESTRUTURAIS
O objetivo dos casadores estruturais é descobrir se os casamentos retornados são
corretos, ou seja, se os casamentos retornados são realmente aqueles que um usuário
especialista escolheria com base na sua própria experiência. Os resultados dos experimentos
são traduzidos por gráficos de revocação e precisão. Valores de similaridade são
abstraídos dos gráficos, já que a preocupação principal consiste em verificar quantos
casamentos corretos estão dentro do grupo dos casamentosb verdadeiros e positivos,
e não em verificar os valores de similaridade propriamente ditos. Para os casos
de baixa eficácia dos algoritmos, é feita uma análise dos casos não resolvidos de
modo a compreender as limitações dos algoritmos propostos.
A utilização dessa técnica se faz da seguinte maneira: são definidos os dois esquemas
que se deseja casar e um conjunto de algoritmos de casamento que será aplicado.
Os resultados de cada experimento são apresentados na forma de uma tabela que contém
os pares de elementos casados e um valor de similaridade para o par. Cada experimento
compreende a execução de uma série de etapas, que obedecem a seguinte ordem:
3.1.3.1 – EXECUÇÃO DOS CASADORES
Na aplicação dessa técnica, os quatro casadores propostos são executados, sendo
que a sua execução obedece a uma determinada ordem. A seqüência de execução é mostrada
na figura 12. A seqüência não precisa ser necessariamente esta, desde que os dois
primeiros algoritmos sejam executados antes dos dois últimos. Essa restrição deve
ser obedecida porque os dois últimos algoritmos utilizam similaridades pré-computadas
para inferir novos valores de similaridades. Para diferenciar os últimos casadores
dos primeiros no tocante ao uso de similaridades pré-computadas, os dois casadores
iniciais são referenciados por casadores de base, enquanto os últimos casadores
são referenciados por casadores de atração.
PADRÃO EQUIV: Os nomes dos elementos XML coincidem com os nomes das colunas
a qual eles se referem. Ambos os nomes representam o mesmo conceito e são escritos
exatamente da mesma forma.

Figura 12 – Seqüência de execução de casadores
3.1.3.2 – COMBINAÇÃO DAS SIMILARIDADES
Outra questão importante é a combinação das similaridades de cada um dos casadores. Os valores de similaridade computados por um casador devem ser combinados com os valores de similaridade computados pelo casador anterior (se houver). A combinação é dada pela média ponderada das similaridades computadas por dois algoritmos adjacentes.
3.1.3.3 – FILTRO DOS RESULTADOS
Somente são apresentados para o usuário os casamentos cuja similaridade tenha passado por uma etapa de filtro. Três formas de filtro são usadas:
·
FILTRO DE
TIPAGEM DOS DADOS: Considera a eliminação de casamentos cujos membros
do par tenham tipos de dados distintos. Os tipos de dados de um esquema relacional
podem ser automaticamente obtidos através da análise dos metadados do esquema. Já
esquemas DTDs não definem tipos de dados, de modo que o trabalho de atribuição dos
tipos de dados dos elementos teve que ser feita manualmente. Uma forma de obterem-se
automaticamente os tipos de dados para elementos de uma DTD envolve análise das
instâncias de documentos XML. Trabalhos futuros podem implementar essa solução para
agilizar o processo de casamento. Igualmente, o uso alternativo de XML Schema resolve
a questão, já que este tipo de esquema permite a definição dos tipos de dados dos
elementos.
·
FILTRO DE LIMIAR: Elimina casamentos
cujo valor de similaridade seja inferior a um limiar pré-estabelecido. Os experimentos
realizados [Mer07] usam um valor de limiar igual a 0.7.
4- CONCLUSÃO
A integração de dados é um assunto que desperta grande interesse não só da comunidade acadêmica, mas também de diversos outros setores. A necessidade das organizações por lucratividade e resultados exige o usufruto da tecnologia de ponta para a diminuição de custos, a agilidade dos seus processos e o encurtamento das fronteiras. Para isso, uma forma de aperfeiçoar seus processos é a utilização da XML como meio de interoperabilidade e integração de sistemas e/ou de dados, conforme demonstrado neste artigo.
A técnica de Casamento de Esquemas que foi apresentada neste artigo, esta voltada somente para casamento entre bancos relacionais e documentos XML, com o armazenamento desses documentos em um servidor nativo XML.
A técnica proposta possui formas inovadoras de analisar as estruturas dos esquemas para inferir a similaridade, visto que as técnicas existentes são limitadas, uma vez que elas ou são projetadas para casar esquemas desenvolvidos no mesmo modelo, como por exemplo, o casamento de dois esquemas relacionais, ou são técnicas genéricas que se aplicam aos diversos modelos, nesse ultimo caso, as técnicas não são adequadas porque elas não exploram as particularidades existentes entre os esquemas para calcular a similaridade.
REFERÊNCIAS BIBLIOGRAFICAS
[Fer02] Ferrandin, Mauri. Integrando Banco de Dados Heterogêneos através do Padrão XML. Dissertação de Mestrado. Florianópolis Outubro 2002.
[Mau05] Mauricio, Cláudio R. Marqueto. Uma Proposta de Mapeamento do Modelo XML Schema para o Modelo Relacional. Dissertação de Mestrado Florianópolis Agosto 2005. p.94-120
[Mat02] Mattoso, Marta; Vieira, Humberto; Gonçalves, Fátima Cristina. XQUERY, XML SCHEMA E XSL. Relatório Técnico Rio de Janeiro Julho 2002.
[Mer07] Mergen, Sérgio Luiz Sardi. Casamento de Esquemas XML e Esquemas Relacionais. Dissertação de Mestrado. Porto Alegre. Março 2007.
[W3c] W3 CONSORTIUM. Extensible Markup Language (XML): activity statement. Disponível em: <http://www.w3c.org.>. Acesso em: 12 de março 2007.
[W3s07] XML Tutorial. Disponível em http://www.w3schools.com/xml/ Acesso em 24 de fevereiro de 2007.

